KAIST AI · Vision-Language Models · Reliable Multimodal Learning
AI for the real world.
I am a Ph.D. student at KAIST AI researching vision-language models, compositional understanding, explainability, data-centric AI, and real-world multimodal systems. My work focuses on making AI models more trustworthy, robust, and practical.
- Computer Vision
- Vision-Language Models
- Representation Learning
- Multimodal Learning
About
Research centered on reliability, reasoning, and deployment.
My work spans vision-language understanding, multimodal reasoning, robust perception, 3D and spatial intelligence, medical imaging, and data-centric approaches that improve AI reliability in practice.
Profile
I am currently pursuing a Ph.D. at KAIST AI after completing an M.S. in Computer Graphics and Visualization at KAIST School of Computing. My research background includes vision-language models, multimodal learning, 3D medical imaging, AR/VR, autonomous driving, and real-world applied AI systems.
Before returning to academia, I worked as a deep learning researcher at FaindersAI, where I built data-centric pipelines, retraining-free model update strategies, multimodal fusion methods, and real-time analytics systems for industry deployment.
Compositional VLM Understanding
Studying how multimodal models understand negation, compositional language, and structured reasoning.
Explainability and Data-centric AI
Improving trustworthiness by fixing data and reasoning failures, not just scaling model size.
3D and Spatial Intelligence
Bridging 2D and 3D understanding for zero-shot spatial reasoning and richer multimodal perception.
Real-world AI Systems
Building robust systems for medical AI, forecasting, autonomous driving, and retail analytics.
Selected work
Publication cards designed for fast scanning.
ECCV 2026
Vision-Language
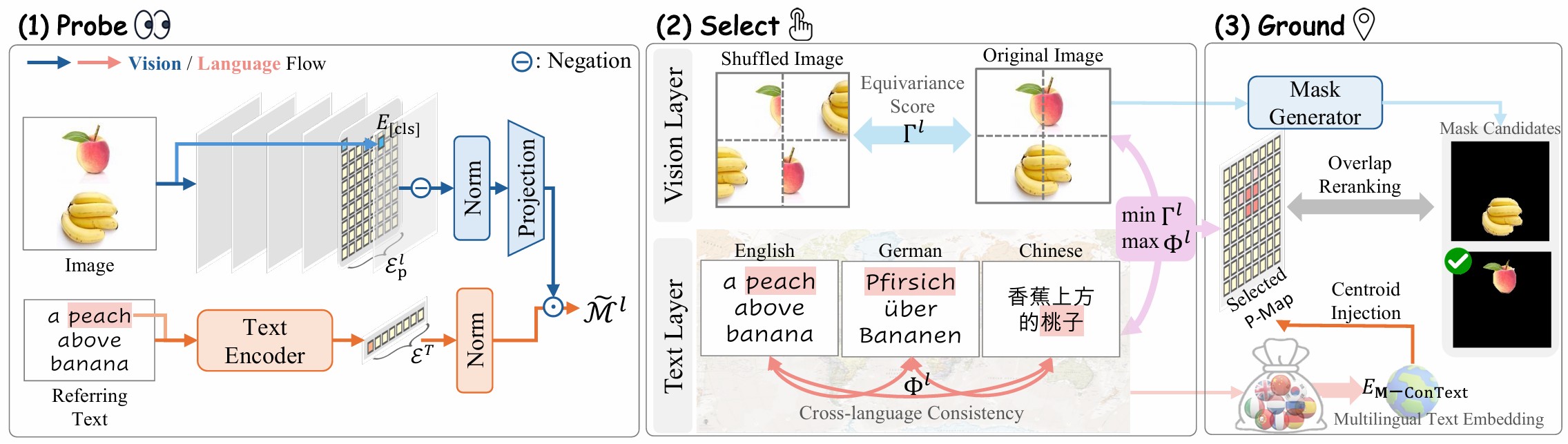
Blind to Position, Biased in Language: Probing Mid-Layer Representational Bias in Vision-Language Encoders for Zero-Shot Language-Grounded Spatial Understanding
Probes mid-layer vision-language representations to uncover positional blindness and language-dependent bias, improving zero-shot language-grounded spatial understanding.
Read paper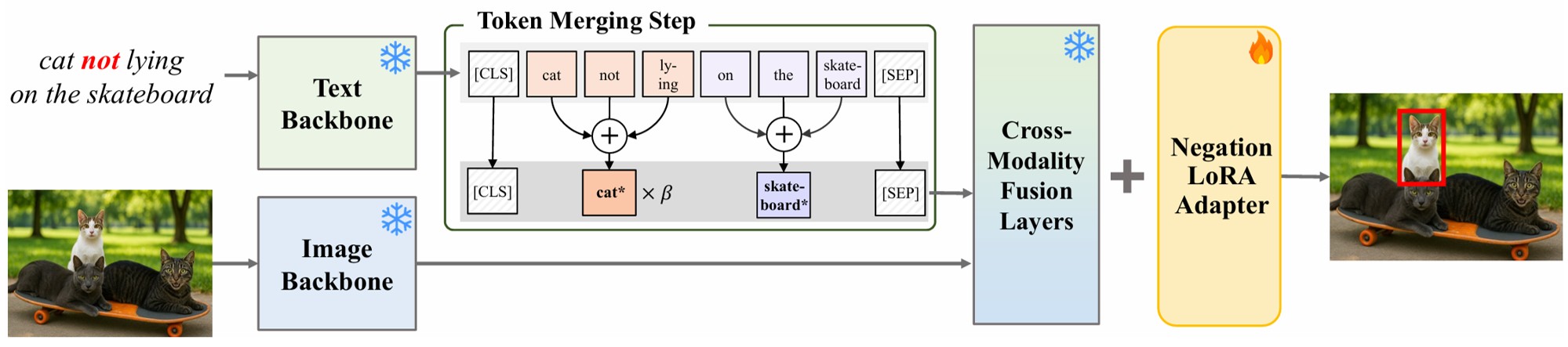
ICLR 2026
Vision-Language
What “Not” to Detect: Negation-Aware VLMs via Structured Reasoning and Token Merging
Tackles the affirmative bias of VLMs when they encounter negation, combining a token-merging module with a reasoning-aware data pipeline.
Read paper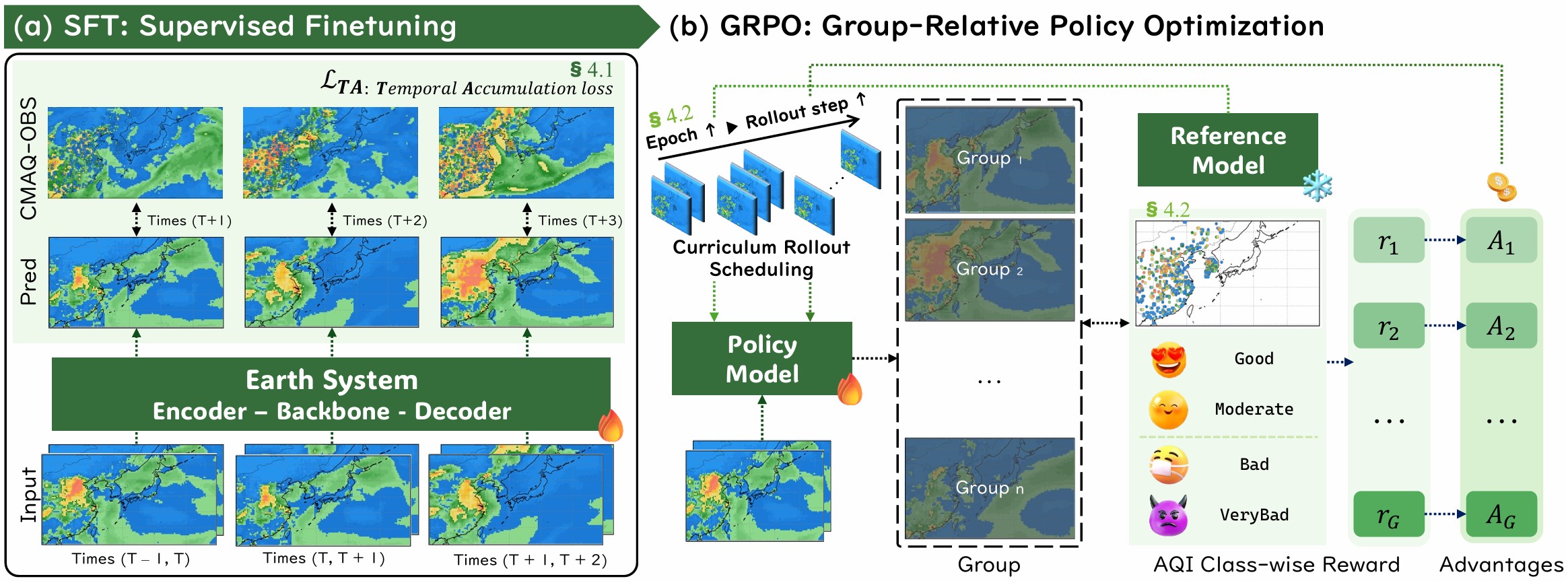
CVPR 2026
Forecasting
Real-Time Long Horizon Air Quality Forecasting via Group-Relative Policy Optimization
CVPR 2026 Compute Transparency Champion
Uses GRPO with asymmetric rewards to reduce false alarms and enable reliable five-day East Asia air quality forecasts.
Read paper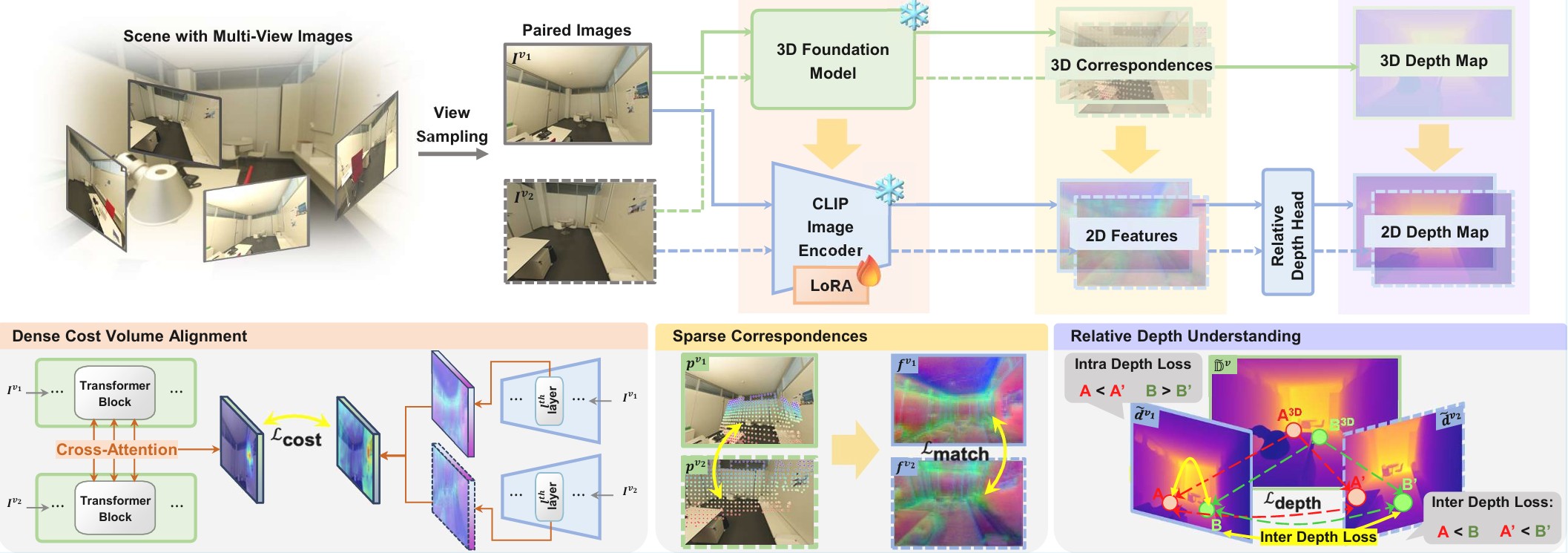
EMNLP 2025
3D VLM
3D-Aware Vision-Language Models Fine-Tuning with Geometric Distillation
Transfers structural knowledge from 3D models into 2D VLMs to improve zero-shot 3D understanding without massive 3D datasets.
Read paper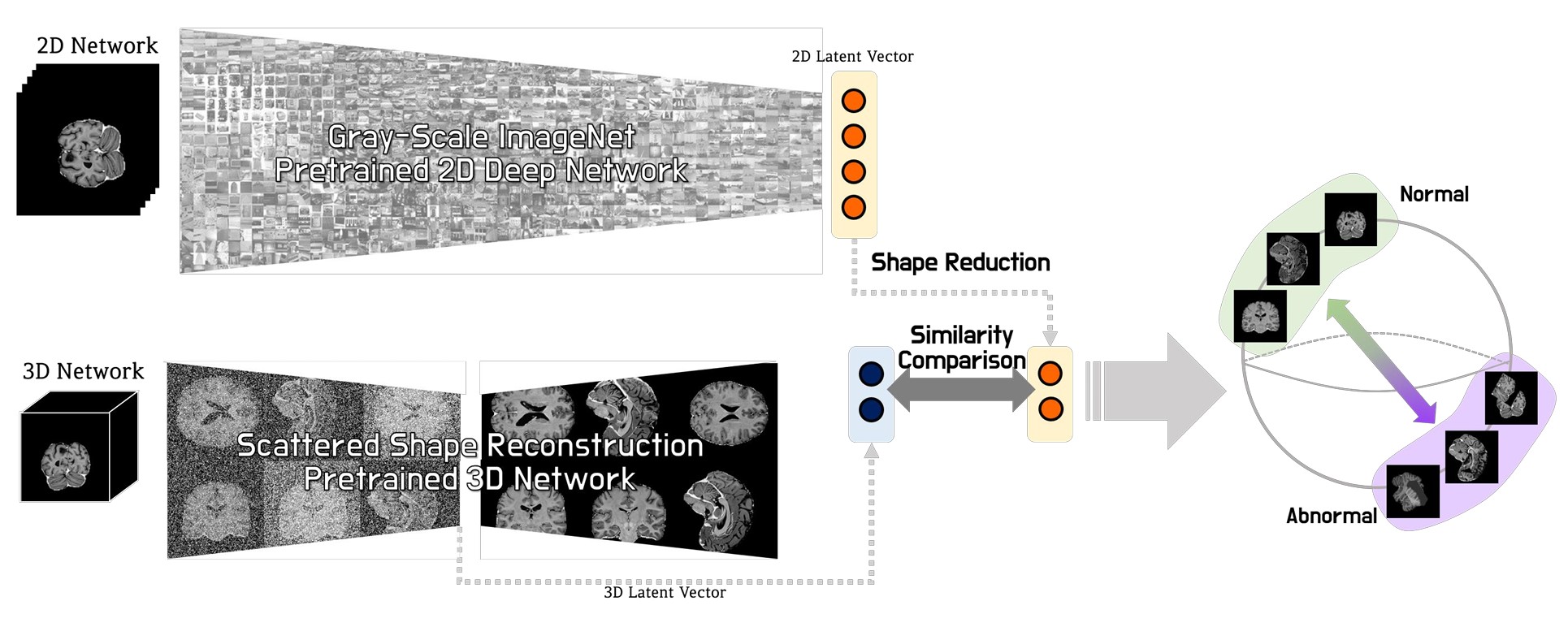
MICCAI 2022
Medical AI
Joint Embedding of 2D and 3D Networks for Medical Image Anomaly Detection
Winning solution for the MICCAI MOOD Challenge, combining local 2D detail and global 3D context for robust anomaly detection.
Read paperEducation
Academic journey
Aug 2024 – Present
Ph.D.
KAIST AI
Computer Vision and Machine Learning Lab · Advisor: Prof. Hyunjung Shim
Research focus: Vision-Language Models, Multimodal Learning · GPA 4.3 / 4.3
Aug 2020 – Aug 2022
M.S.
KAIST School of Computing
Computer Graphics and Visualization Lab · Advisor: Prof. Jinah Park
Research focus: 3D Medical Imaging, AR/VR · GPA 3.88 / 4.3 · MICCAI MOOD Challenge 1st Place in 2021 and 2022
2017
Visit
University of California, Berkeley
Computer Science
Mar 2016 – Aug 2020
B.S.
GIST
Electronic Engineering and Computer Science
Graduated salutatorian · Best Thesis Award · Minor in Business Administration and Sociology
Experience
Research and industry
2022 – 2024
Industry
FaindersAI · Deep Learning Researcher
Seoul, Korea
- Built a data engine to generate high-quality segmentation data using a feature-based VLM filtering pipeline.
- Studied retraining-free model update strategies and multimodal fusion across diverse sensor inputs.
- Engineered a real-time retail analytics system that achieved 2× competitor accuracy.
2019 – 2020
Research
Machine Learning and Vision Lab · Research Intern
Gwangju, Korea
- Designed a scheduled training method for robust long-tailed object detection in autonomous driving.
2017 – 2018
Research
Aerospace Propulsion Lab · Research Intern
Gwangju, Korea
- Studied parallel computing and GPU acceleration for high-performance workloads.
Projects
Applied systems across medical AI, XR, and human-centered design.
PM2.5 Interaction Visualization
3D label-free visualization of fine dust interaction with cells using optical diffraction tomography.
SketchScope
Interactive virtual science museum platform with sketch-based volume exploration, VR interaction, and HoloLens 2 support.
Project pageForMixMatch
Virtual fashion coordination service exploring image-based try-on and layout design for confident online shopping decisions.
Project deck